Retrieval-Augmented Generation, or RAG, is a way of making large language models, like the ones used in intelligent chatbots, more useful by giving them access to extra information outside of their usual training data. Normally, these language models are trained on huge amounts of text data and use complex systems to generate responses. However, once trained, they can’t pull in new information on their own. RAG solves this problem by connecting these models to other reliable data sources, like a company's internal documents, without needing to retrain the entire model. This setup makes it more affordable to keep responses accurate, relevant, and focused on specific subjects or areas.
RAG is important because it helps improve the quality of chatbot answers. Large language models can sometimes give wrong information or general answers when people want something more specific. For example, they may not have up-to-date knowledge or may give incorrect answers if they don’t know about a particular subject. This can happen because the model's training data is static, meaning it doesn’t automatically update with new information. Also, LLMs can confuse terms that look similar but have different meanings across contexts. So, a language model might answer confidently even when it’s wrong, and that can make users lose trust in the chatbot.
With RAG, the model retrieves current information from reliable sources before responding, which allows users to trust the output more. It’s like giving the model a way to check for recent facts before answering, making sure the response is based on the latest information. Since this setup gives organizations control over what the model reads from, they can make sure it only pulls information from trusted sources.
The benefits of RAG go beyond just improving accuracy. It’s also a cost-effective way to add new information to a language model without having to retrain it, which can be expensive and time-consuming. Instead of rebuilding the whole model, RAG lets developers connect it to relevant data sources. This keeps the model fresh and useful while also reducing costs. Also, RAG enables models to present the latest research or news, as developers can link the model to live data sources. This means that when a user asks a question, the model can provide a well-informed answer that includes up-to-date knowledge.
Another benefit of RAG is that it improves user trust in the model. When RAG is used, responses can include sources or citations, so users know where the information is coming from. If they need more details, they can even check these sources themselves. This adds transparency to the responses, helping users feel confident in what they are reading.
For developers, RAG offers flexibility and control over how the model performs. They can adjust the sources to match new requirements or different user needs. For example, in a workplace setting, they can restrict the information access based on the employee’s role or the sensitivity of the data. This ability to change and test sources makes it easier for developers to maintain a reliable chatbot over time and fix issues when they arise. By having control over the model’s data sources, developers can fine-tune how the model answers, improving accuracy in a wide range of applications.
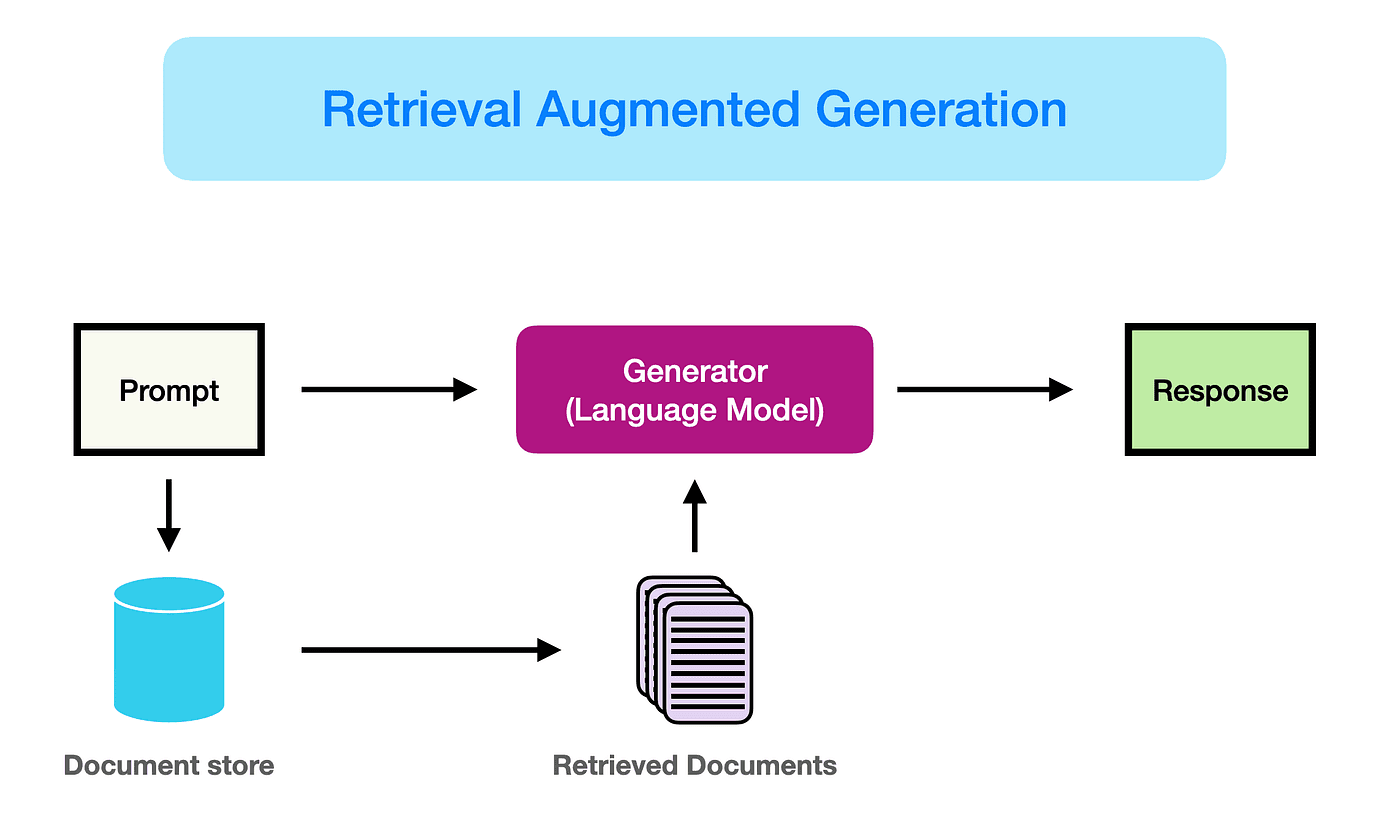
When RAG is set up, it follows a series of steps to produce accurate responses. First, there is the creation of an external data source. This is where all the extra information that the model wasn’t trained on is stored, which could be anything from company policies to customer service guides. Then, the user’s question is matched with relevant data from this source. For example, if an employee asks about their annual leave, the model can retrieve the specific policy document and even check the employee’s leave balance. This process ensures the model pulls only what is relevant.
Once the information is selected, it’s added to the user’s question in a way that helps the model understand the full context before generating a response. This process, known as prompt augmentation, ensures the model has all it needs to answer accurately. Developers then keep this external data updated, whether by setting up automatic updates or periodic checks, to make sure it stays relevant.
RAG can be improved even further with semantic search technology, which lets the model locate the most accurate data across large collections of documents. This type of search goes beyond simple keyword matching. Instead, it uses techniques to understand what the user’s question really means, retrieving only the most relevant documents or passages. For example, if the model is asked how much money was spent on repairs last year, semantic search can find the exact figures from financial reports without pulling unnecessary information. This way, RAG combined with semantic search improves the model’s response quality and keeps the process efficient for developers.
In simple terms, RAG gives language models a way to check the latest information before answering questions, allowing them to provide more accurate, trusted, and current responses. It’s like an upgrade that makes chatbots smarter, more reliable, and easier for developers to manage without high costs or complex training.



